
Similarly one may ask, how is gradient descent used in machine learning?
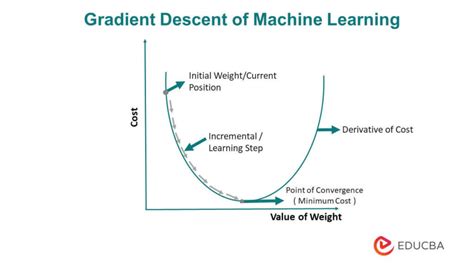
Gradient descent is an optimization algorithm that's used when training a machine learning model. It's based on a convex function and tweaks its parameters iteratively to minimize a given function to its local minimum.
Beside above, what is batch gradient descent in machine learning? Batch gradient descent refers to calculating the derivative from all training data before calculating an update. Stochastic gradient descent refers to calculating the derivative from each training data instance and calculating the update immediately.
People also ask, what does a gradient descent algorithm do?
Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. To find a local minimum of a function using gradient descent, we take steps proportional to the negative of the gradient (or approximate gradient) of the function at the current point.
How do you read a gradient descent?
Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) Adjusts the parameters of the equation to move in the direction of the negative slope. This gradually brings you to a minimum point.



